mongodb索引详解(Indexes)
索引介绍
索引在mongodb中被支持,如果没有索引,mongodb必须扫描每一个文档集合选择匹配的查询记录。这样扫描集合效率并不高,因为它需要mongod进程使用大量的数据作遍历操作。
索引是一种特殊的数据结构,它保存了小部分简单的集合数据。索引存储了一些特殊字段,并将其排序。
从根本上讲,索引在mongodb中和其他数据库系统是类似的。mongodb规定了索引的集合级别、支持索引任何字段或者子字段在mongodb文档集合中。
索引优化查询方案
要考虑数据之间的关系,做查询优化。
创建索引支持常见的面向用户的查询,确保扫描读取文件最小数量。
索引可以优化特定场景中的其它业务的性能。
排序返回数据
来看看一个索引的具体例子(其实就相当于我们查询字段一样的)
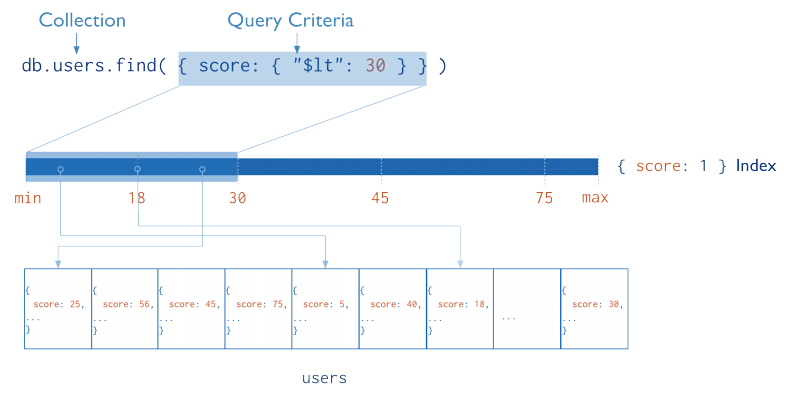
上图展示了有索引和无索引的查询方式,目测都可以看出效率。
大数据查询
当我们使用索引的时候,查询时候根据对应字段在索引中查询,无需将数据加载到内存中,直接扫描索引拿数据。这些大数据查询是非常有效率的。
索引类型
MongoDB提供了一些不同的索引类型支持的数据和查询的具体类型
- Default _id (默认_id索引)
所有mongodb默认都有一个_id字段索引,如果我们不指定_id的值会自动生成一个ObjectId值。
该_id索引是唯一的,并且可以防止客户端对_id字段值相同插入两个。# 查询articles集合的索引 db.articles.getIndexes(); # 添加titlei字段索引,并且为升序 db.articles.ensureIndex({title:1}); #重构索引(慎用) db.articles.reIndex();注意:索引排序规则升序:1,降序-1 -
Single Field (单字段索引)
mongodb允许定义单个字段的索引,与default _id一样,只是字段不同。
-
Compound Index (复合索引[多字段索引])
mongodb中可以自定多个字段的索引。例如,如果一个复合指标包括
{userid:1,score:-1 },索引排序第一的用户名后,在每一个用户标识符值,按得分++倒序++排序。{ "_id": ObjectId(...), "item": "Banana", "category": ["food", "produce", "grocery"], "location": "4th Street Store", "stock": 4, "type": "cases", "arrival": Date(...) }创建方法:
# 创建item、stock字段的复合索引,并且升序排序 db.products.ensureIndex( { "item": 1, "stock": 1 } )注意:Hashed 字段不能创建索引,如果创建将出现错误Application Sort Order 使用案例:降序用户名升序时间。
# 查询结果集中排序 db.events.find().sort( { username: -1, date: 1 } ) # 查询结果集中排序 db.user_scores.find().sort({score:-1,date:-1}).limit(1) # 执行相关查询可以看出查询效率大大提高 - MultiKey Index (多键索引)
官方文档中给出这样一个案例:
{ userid:"marker", address:[ {zip:"618255"}, {zip:"618254"} ] }# 创建索引,并将zip升序排列 db.users.ensureIndex({"address.zip": 1}); # 假如我们做这样的查询 db.users.find({"addr":{"$in":[{zip:"618254"}]}})注意:你可以创建 多键复合索引(multikey compound indexes) -
Geospatial Index (地理空间索引)
db.places.ensureIndex( { loc : "2dsphere" } ) - Text Indexes (文本索引)
文本索引是在2.4版本更新的,提供了文本搜索文档中的集合功能,文本索引包含:字符串、字符数组。使用
$text做查询操作。2.6版本 默认情况下使文本搜索功能。在MongoDB 2.4,你需要使文本搜索功能手动创建全文索引和执行文本搜索# 创建文本索引 (2.6你就不用这么麻烦了哦) db.articles.ensureIndex({content:"text"});复合索引可以包含文本索引 称为:复合文本索引(compound text indexes),但有限制
1. 复合文本索引不能包含任何其他特殊索引类型,比如:多键索引(multi-key Indexes) 2. 如果复合文本索引包含文本索引的键,执行$text查询必须相同查询条件。可能翻译不对原文: (If the compound text index includes keys preceding the text index key, to perform a $text search, the query predicate must include equality match conditions on the preceding keys1) - Hashed Indexes (哈希码索引)
哈希索引在2.4版本更新的,将实体的的哈希值作为索引字段,
# 给user_scores的score字段创建一个哈希索引 db.user_scores.ensureIndex( { score: "hashed" } )
索引的属性
除了众多索引类型的支持以外,还可以使用各种属性来调整性能。
- TTL Indexes
它是一个特殊的索引,可以在某个时间自动的删除文档集合的索引。对于一些信息数据比如说日志、事件对象、会话信息,只需要存放在数据库一个特定期限。使用限制:
1. 不支持复合索引 2. 必须是date时间类型字段 3. 如果是date数组,按照最早时间过期。TTL index不保证过期时间立即删除,
后台任务没60秒运行删除,
依赖于mongod进程 -
Unique Indexes
# 创建唯一索引 db.members.ensureIndex( { "user_id": 1 }, { unique: true } )注意:如果字段为null,那么就以null值,但不能重复插入空值。如果collection中有两个实体唯一索引字段为空,则不能创建唯一索引也就是说,我们还可以利用它作为类似于关系型数据库的唯一约束。
# 强制插入空值对象后报错 > db.users.insert({content:"unique testing"}) WriteResult({ "nInserted" : 0, "writeError" : { "code" : 11000, "errmsg" : "insertDocument :: caused by :: 11000 E11000 duplicat e key error index: test.users.$dsadsadsa dup key: { : null }" } }) - Sparse Indexes
db.addresses.ensureIndex( { "xmpp_id": 1 }, { sparse: true } ) - background属性 高效修改/创建索引
在项目运行中,如果我们直接采用前面的方法创建索引或者修改索引,那么数据库会阻塞建立索引期间的所有请求。mongodb提供了background属性做后台处理。
db.addresses.ensureIndex( { "xmpp_id": 1 }, {background: true } )我们知道如果哦阻塞所有请求,建立索引就会很快,但是使用系统的用户就需要等待,影响了数据库的操作,因此可以更具具体情况来选择使用background属性
索引名称
# 自动生成索引名称
db.products.ensureIndex( { item: 1, quantity: -1 } )
# 被命名为: item_1_quantity_-1
# 自定义索引名称
db.products.ensureIndex( { item: 1, quantity: -1 } , { name: "inventory" } )
索引交叉
在2.6版本中更新的,这块没有深入了解。
管理索引
# 添加/修改索引
db.users.ensureIndex({name:"text"});
# 删除集合所有索引
db.users.dropIndexes();
# 删除特定索引 (删除id字段升序的索引)
db.users.dropIndex({"id":1})
# 获取集合索引
db.users.getIndexes();
# 重构索引
db.users.reIndex();
总结
索引分类:
- Default _id (默认_id索引)
- Single Field (单字段索引)
- Compound Index (复合索引[多字段索引])
- MultiKey Index (多键索引)
- Geospatial Index (地理空间索引)
- Text Indexes (文本索引)
- Hashed Indexes (哈希码索引)
为什么要使用索引?想想查字典原理就明白了。
声明:本人英文水平有限,部分翻译或者理解错误请谅解。也可以偷偷告诉我,更新该文章!
 关注微信公众帐号
关注微信公众帐号